
De l'art d'analyser des données dans Excel, ou ailleurs
Voici une série d'articles autour de l'analyse de données sous Excel. Le but de ces articles n'est pas d'être exhaustif et de vous faire découvrir toutes les fonctionnalités d'Excel, des centaines de livres traitent déjà de ce sujet, ni de faire de vous des héros de la donnée. La modeste ambition de ces quelques lignes est de vous armer du minimum vital pour aborder des projets de données simples et de voir des concepts communs à tout projet d’analyse de données : depuis leur organisation des données à leur analyse avec un outil que tout le monde possède, Excel, dans le but de répondre à une question que l’on se pose.
Vous n'avez pas besoin de beaucoup de données ni d'outils. Vous avez besoin de répondre à une question
Se cantonner à répondre à une question est primordial, car nous pouvons facilement nous faire emporter par un jeu de données et les dernières technologies à la mode. Certes une question peut se préciser, voire se développer au cours d’une analyse, mais au départ de toute cette exploration, un problème à résoudre, même flou, est un minimum vital. Cette question peut même parfois juste être réduite une hypothèse.
Il m’est arrivé d’explorer un jeu de données de voitures et d’étudier le nombre de voitures de chaque couleur. Puis de faire un graphe de distribution par couleur. Les voitures vertes sont les plus nombreuses. Aucun intérêt. Si, à l’inverse, j’avais postulé que les voitures blanches devaient être majoritaires car plus vendues en France, l’analyse aurait été plus intéressante. La réponse, d’inintéressante au possible, serait devenue surprenante et donc sujette à investigation.
Pour répondre à une question, vous devez utiliser le minimum de données nécessaires. Pas besoin d’aller chercher des centaines de millions de points de données, si une centaine suffisent à répondre à votre question.
Mettons que vous ayez une piscine municipale à gérer, et votre responsable vous demande de l’aider à prévoir les pics d’affluence. Il va vraisemblablement vous falloir peu de temps pour trouver un coupable idéal : la température extérieure. Plus il fait chaud, plus il y a de monde à la piscine. Fier de votre hypothèse révolutionnaire, vous passez à la caisse et sortez les données de vente de tickets d’entrée de ces quatre dernières années. Vous faites une petite régression linéaire pour obtenir une courbe qui lie l’influence aux températures extérieures. Bingo! Votre courbe permet de prévoir à 93% les pics d’affluence. Vous n'avez eu besoin que de 365 x 4 lignes + 1 (pour l'année bissextile) pour résoudre votre problème.
La question qui va se poser maintenant est la suivante: est-ce assez ou va-t-il falloir continuer ? Votre responsable sera peut-être content. Mais peut-être sera-t-il déçu. Il n’avait pas besoin de vous pour savoir que la plupart des pics d’affluence arrivent les jours de grande chaleur. Encore fallait-il le prouver. Peut-être que ce 93% n’est pas assez bon et vous devez aller voir à quoi correspondent ces quelques écarts. Et les quatre années de données de la caisse ne suffiront peut-être plus à répondre à vos questions.
Ce petit exemple nous montre l’ensemble des problèmes très terre-à-terre qui se cachent derrière de grands mots tels que la data, ou le machine learning (la régression linéaire est, après tout, une technique de base de l'apprentissage machine). Ces mots sont des ensemble de concepts plus ou moins bien définis, plutôt moins que plus d’ailleurs. La réalité qui se cache derrière tout cela est souvent bien moins ésotérique. Et si vous avez juste besoin d’un bout de papier et d’un crayon pour résoudre votre problème, alors ne vous privez surtout pas de l'utiliser.
Pourquoi Excel ?
Nous pourrions nous poser la question de la pertinence d'Excel en 2023. En effet, vous avez certainement entendu parler d'outils tels que Looker Studio, Tableau ou, pour rester chez Microsoft, Power BI. Et les équipes marketing de ces outils ont fait du très bon travail pour reléguer Excel au second plan. Mais ce serait oublier que ces outils occupent une place différente sur l'échiquier de la data.
Chaque logiciel ou langage de programmation n'est qu'un outil, adapté à certaines situations. Par exemple, Looker/Data Studio est construit sur Google Analytics, lui-même construit sur les données de trafic de sites internet. C'est donc un outil bâti autour de l'analyse de ces éléments. Power BI présente des avantages certains au niveau du partage des visuels produits, mais sa mise en place reste lourde. Python est un bon langage pour faire des maths, des modèles d’analyse, mais je préfère pour le reste travailler avec Javascript et ses bizarreries.
Or, les projets avec base de données relationnelles et/ou de l'analytique avec un outil de type Looker ou Power BI sont plus lourds à mettre en place. Excel est plus rapide et plus flexible, et permet d'avoir une vision transversale de toutes les étapes d'un projet d'analyse ou de reporting. Des ancêtres d’Excel existent depuis les années 60, la présentation sous forme de tableur a quelque chose de naturel pour nous. Cela était valide il y a 50 ans, ce le sera vraisemblablement aussi dans 50 ans.
Les plus d’Excel:
- Excel est disponible partout, tout le monde le connait et sait s'en servir, pour le meilleur et pour le pire.
- Un projet Excel est rapide à mettre en œuvre. Certains problèmes ne nécessitent pas de quantités astronomiques de données pour être résolus et une analyse rapide sous Excel est souvent suffisante.
- Excel couvre tout le spectre de la data: stockage, organisation, analytique (descriptif, diagnostic, prédictif, prescriptif) et visualisation. Il nous permet également de manipuler directement ces différents éléments.
- Il offre des outils généralement plus flexibles, notamment pour la visualisation.
- Forts de centaines de millions d'utilisateurs, Excel est capable d'évoluer et d'intégrer toujours plus d'outils (Power Query, Python,...)
Les moins d'Excel:
- Impossibilité de travailler sur des volumes de données importants si l'on se cantonne à un fichier Excel pour le stockage des données. La limitation saute si l'on se connecte à une source de données extérieure.
- L'automatisation et la mise à jour des rapports et visuels nécessitent une mise en place soignée, comprendre ici qu’il est facile de faire planter un rapport Excel lors d’une mise à jour.
- Les fonctionnalités de partage et de protection des fichiers sont des ajouts peu fonctionnels, des outils comme Power BI seront souvent plus adaptés pour le partage de rapports avec des personnes extérieures.
En résumé, Excel permet de voir tous les éléments du traitement de la donnée dans un seul logiciel : stockage, organisation, traitement analytique et visualisation. Il y a très peu d’abstraction dans Excel, ce qui en fait un outil intéressant pour débuter, mais parfois aussi pour aller plus loin. De plus, Excel évolue rapidement et devrait par exemple bientôt intégrer Python.
Les données avec les données, l'analyse avec l'analyse
Lorsqu'un projet dépasse la taille d'une feuille de travail, il est très important de commencer à organiser ses onglets ou fichiers et de bien séparer les objectifs de chaque partie. C'est un peu comme en cuisine. Si vous êtes seul, vous pouvez manger dans votre cuisine ou dans votre canapé, cela n'a pas d'importance. Si vous avez des invités, vous allez éplucher les légumes dans la cuisine, et vous servirez vos plats dans le salon. Pas l'inverse. Et si devez organiser un banquet pour 100 personnes, il vous faudra une équipe et une organisation bien huilée. L'analyse de données, c'est exactement la même chose.
Une place pour chaque chose et chaque chose à sa place.
Plus généralement, nous pourrions parler de séparation des préoccupations. Même si ce concept nous vient de la programmation, il convient bien à ce que nous essayons de décrire ici. Il conviendrait d'ailleurs à bien d'autres domaines comme l'architecture, la cuisine, la politique (et la séparation des pouvoirs) et bien d'autres encore. Chaque chose a sa place.
Dans le traitement des données, il est important de bien séparer les données, leur analyse et leur présentation, et de clarifier aussi bien pour vous que pour vos interlocuteurs quel onglet ou fichier fait quoi. Cela est d'autant plus vrai que l'ampleur du projet est importante. Mélanger analyse et données vous expose, entre autres, à des problèmes de maintenance de vos fichiers. D'ailleurs, je dirais que quelqu'un qui a clairement conscience de la différence entre un tableau d'analyse et un tableau de données possède déjà une culture générale de la donnée non négligeable.
Nommer ses dossiers, fichiers ou onglets de façon cohérente
La séparation des préoccupations, c'est bien joli, mais voyons comment cela se passe d'un point de vue pratique, et donnons des noms à nos dossiers, fichiers, et autres onglets en tout genre.
Passons en revue certains des éléments de la dénomination que nous pouvons utiliser :
- Un préfixe: j'utilise l'ordre de l'alphabet ASCII pour ordonner les éléments d'un fichiers. Les fichiers avec un "00" comme préfixe seront ainsi en haut du tri de fichiers. Je réserve le "zz" pour les fichiers d'archives qui seront ainsi triés à la fin.
- Le nom du projet ou de l'analyse: dans le cas de plusieurs analyses ou projets. Quand un fichier mélange plusieurs projets ensemble, nous allons les identifier. Un exemple typique est un fichier de rapport financier avec un rapport "Chiffre_affaire" et un rapport "Inventaire".
- La désignation de l'objectif du fichier: "DATA" par exemple pour du stockage de données, "ANALYSE" pour...de l'analyse et des graphiques, "CONSO" pour de la consolidation de données, "NET" pour du nettoyage.
- La date (Année_Mois_Jour): un classique au panthéon des classiques, le datage des fichiers. Pas besoin d'explications si ce n'est qu'il est plus judicieux de mettre la date qu format "AAAA_MM_JJ" car cela permet de classer les fichiers avec le même nom dans un ordre chronologique. Si le jour est en premier, le classement de fichier se fera d'abord en fonction... des jours du mois et ensuite des mois et années.
- La version: une alternative à la datation des fichiers est d'utiliser des versions de fichier "V1", "version_2",...
Vous pouvez bien sûr mixer ces éléments à votre guise et même, soyons fous, en inventer d'autres. Passons maintenant à quelques exemples.
Pour un fichier de rapport financier, nous pouvons utiliser un préfixe de classification suivi d'une désignation de l'objectif et la date. Le contenu d'un fichier pourrait rassembler les fichiers suivants:
- "00_DATA_Finance_2023_03_01"
- "01_RAPPORT_Finance_2023_05_01"
- "zz_DATA_Rapport_financier_2023_01_01"
- "zz_DATA_Rapport_financier_2023_02_01"
- "zz_DATA_Rapport_financier_draft_2023_01_01"
Pour une analyse simple avec les données et l'analyse dans le même fichier, nous n'aurions vraisemblablement pas besoin de la date, ni d'ordonner les onglets grâce un préfixe, ce qui nous donnerait un fichier lambda avec un onglet "DATA" et un autre "ANALYSE".
Enfin, voici un exemple réel de structure de fichier de rapport des ventes :
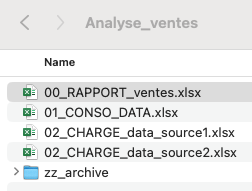
Lorsque j'ouvre le fichier, je vois tout de suite le fichier important en haut ; la plupart des collaborateurs n'ira d'ailleurs ouvrir que le fichier "00_RAPPORT_ventes". Les 2 fichiers en "02" chargent des données depuis 2 sources différentes avec Power Query. Puis, toujours avec Power Query, je viens taper dans ces 2 fichiers pour consolider et transformer les données dans le fichier "01_CONSO", et le "00_RAPPORT" vient taper dans ce fichier pour s'alimenter en données.